普段、Linuxのパソコンを使っていて、「grep」というコマンドを使うことがあるだろうか?
検索してヒットした記事を読んでも、まるでちんぷんかんぷん。
ざっくり言えば、「grep」はファイル内検索のコマンドだ。
では、前回「みんなが知りたいLinuxコマンド「ファイル 検索」と「ファイル 削除」|ざっくりLinux!- 71」で書いた、「find」とはどう違うのか?
今回も、あくまでざっくりと書いてみたい。
grepコマンドとは
grepについては、Linux Essentialsのドキュメント「3.2 ファイルの検索と展開 レッスン2」に書かれている。
grepとは、“global regular expression print” (汎用正規表現の表示)の略。ここまでくると、前回のように元の英語表示からコマンドを想像することは、難しそうだ。
このドキュメントによると、grepは、システム管理者が繰り返し発生する情報を、自動的に識別して監視するために使うツールとしている。具体的には、指定されたパターン(文字列など)を、ファイル内で検索するコマンドのこと。
つまり、
- システム内の特定の「ファイル」を検索するコマンドが「find」
- ファイル内の特定の「文字列」を検索するコマンドが「grep」
だということ。
これで少しスッキリした。
もう少し詳しく言えば、grepは「ファイルを開くことなく、特定の文字列が含まれているかどうかを調べることができる」ということだ。そして、このgrep、実は高速検索で優秀らしい。
だが、Linux初心者にとっては、おそらくほとんど使うことがないだろう。
なぜなら、「Linux初心者がぶち当たるコマンドの壁〜専門用語がわからない|ざっくりLinux!- 69」にも書いたとおり、現在のLinuxディストリビューションは、ほぼコマンドを使うことなく、普通のパソコンとして機能する。
あえていうならば、「grep」を含めた全てのコマンドは、プログラマーやITエンジニアが使うもの、あるいはITエンジニアとしての資格の勉強をする人のためのものとしか思えない。
それでも、みんなが知りたいLinuxコマンドが「grep」なのだ。
grepの使い方
grepの基本的な使い方は以下の通り。
端末を開いて、以下の通り入力すれば、検索結果が表示される。
$ grep 検索したい文字列 ファイルのパス例として、ドキュメントフォルダ内にTest.txtというファイルを置いてある。ここには「Hello World!」とだけ書いてある(どこかで聞いたフレーズ?)。
このファイル内にある「Hello」という文字列を検索すると、以下の通り表示された。
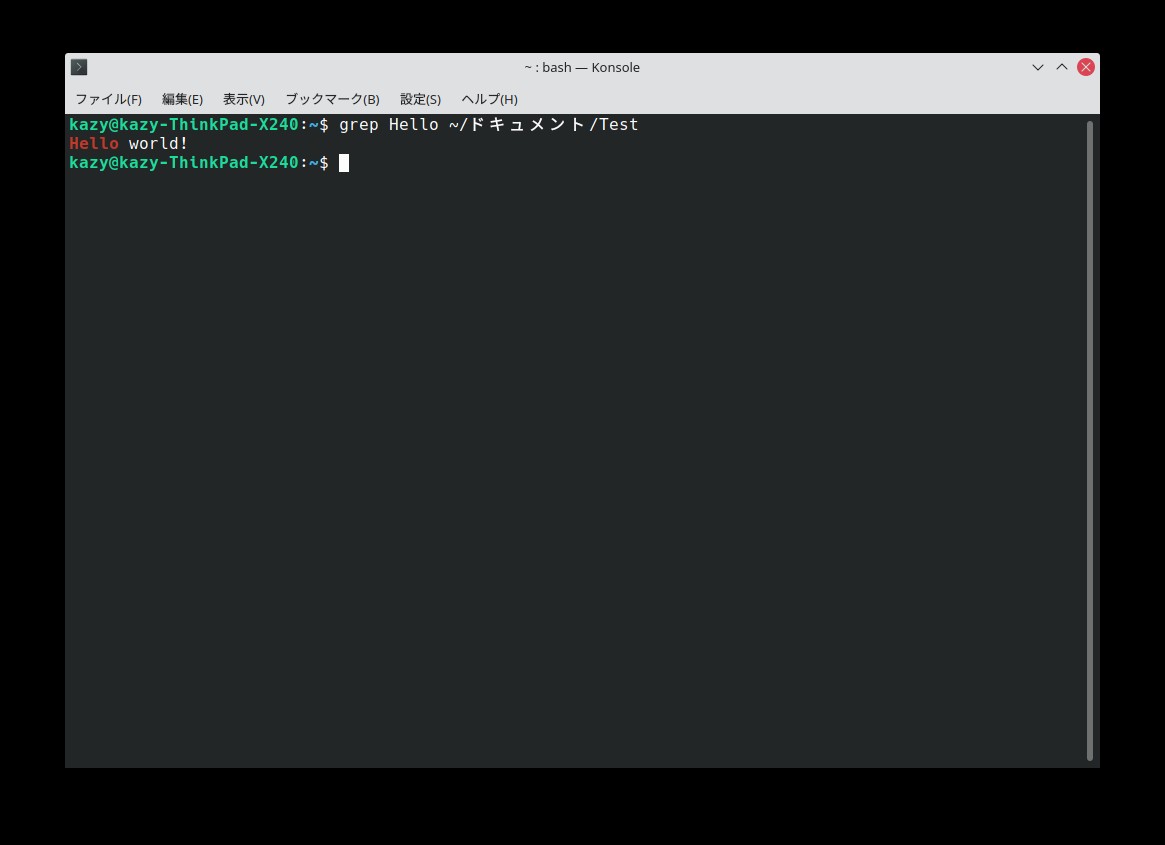
検索に指定された文字列は、赤で強調されて表示される。
実際、テキストファイルには上記のフレーズ1行しか書いていないため、検索結果も1行しか表示されないが、指定文字列が含まれる行が複数ある場合は、含まれる行全てを表示する(Test2.txtの検索結果:下記画像)。
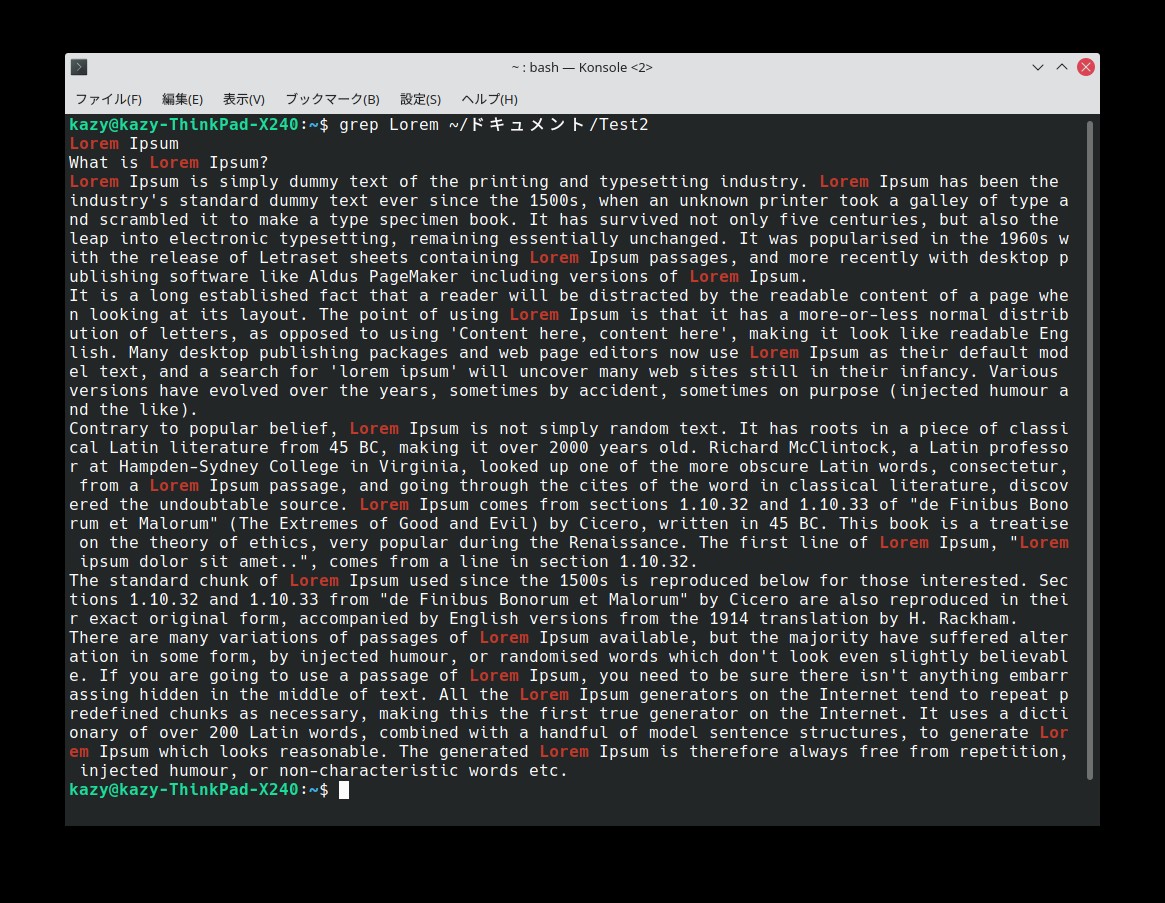
また、デフォルトでは大文字と小文字は区別して表示される。
よく使う便利なオプション
grepは、文字列の前に以下オプションを入れて検索することで、より便利に検索することができる。
- 「-i」:大文字と小文字を区別しない
- 「-v」:検索文字列に一致しない行を表示する
- 「-r」:再帰的に検索する(指定されたディレクトリとそのサブディレクトリ内の全てのファイルを検索する)
- 「-c」:指定文字列で一致した数を表示する
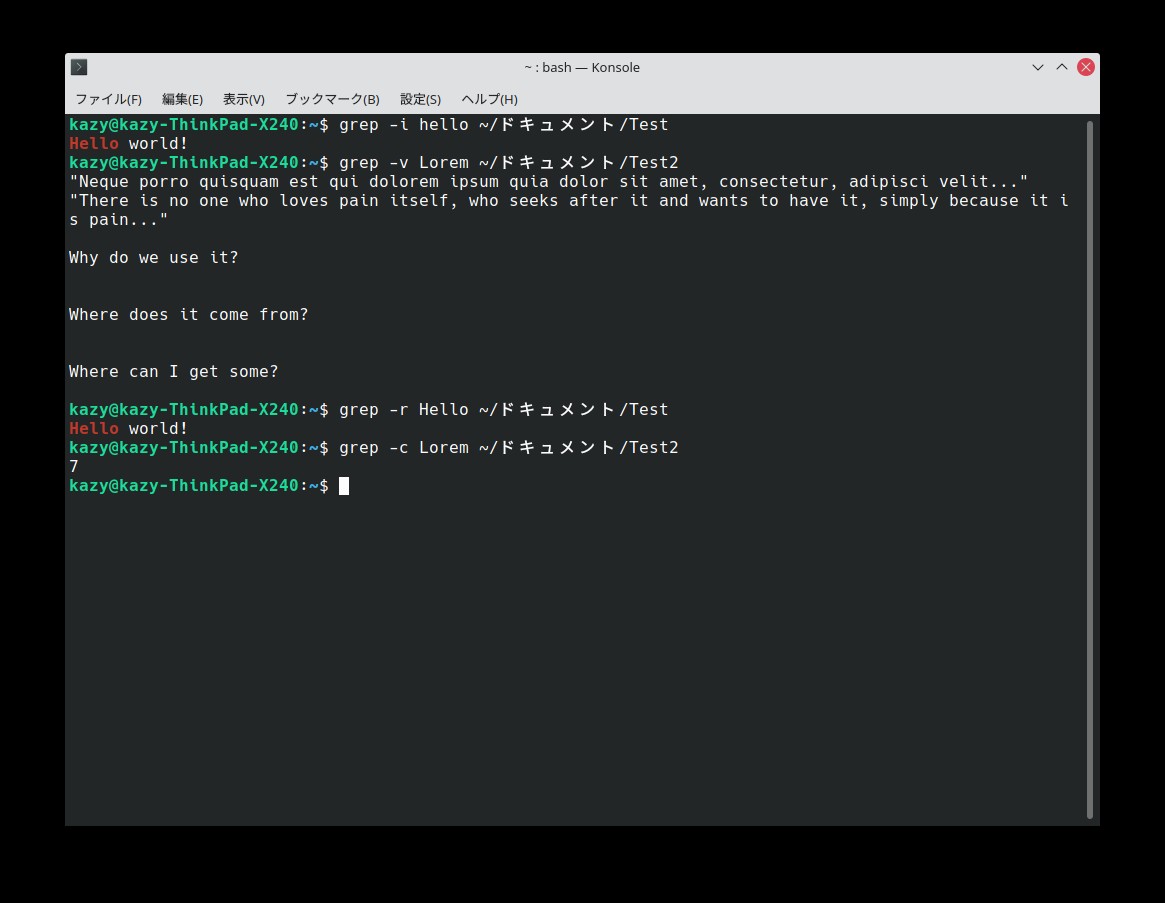
特に「-v」(一致しない行を表示)は、必要な単語が入っていない行だけ削除したい時などに使えて、便利だ。
これ以外にもいろいろなオプションがあるが、よく使いそうなオプションだけざっくりと紹介した。
さらに詳しく知りたい場合は、便利なマニュアルコマンド「man」を使ってみよう。以下のように、このコマンドの後に知りたいコマンドを入力するだけだ。
$ man grep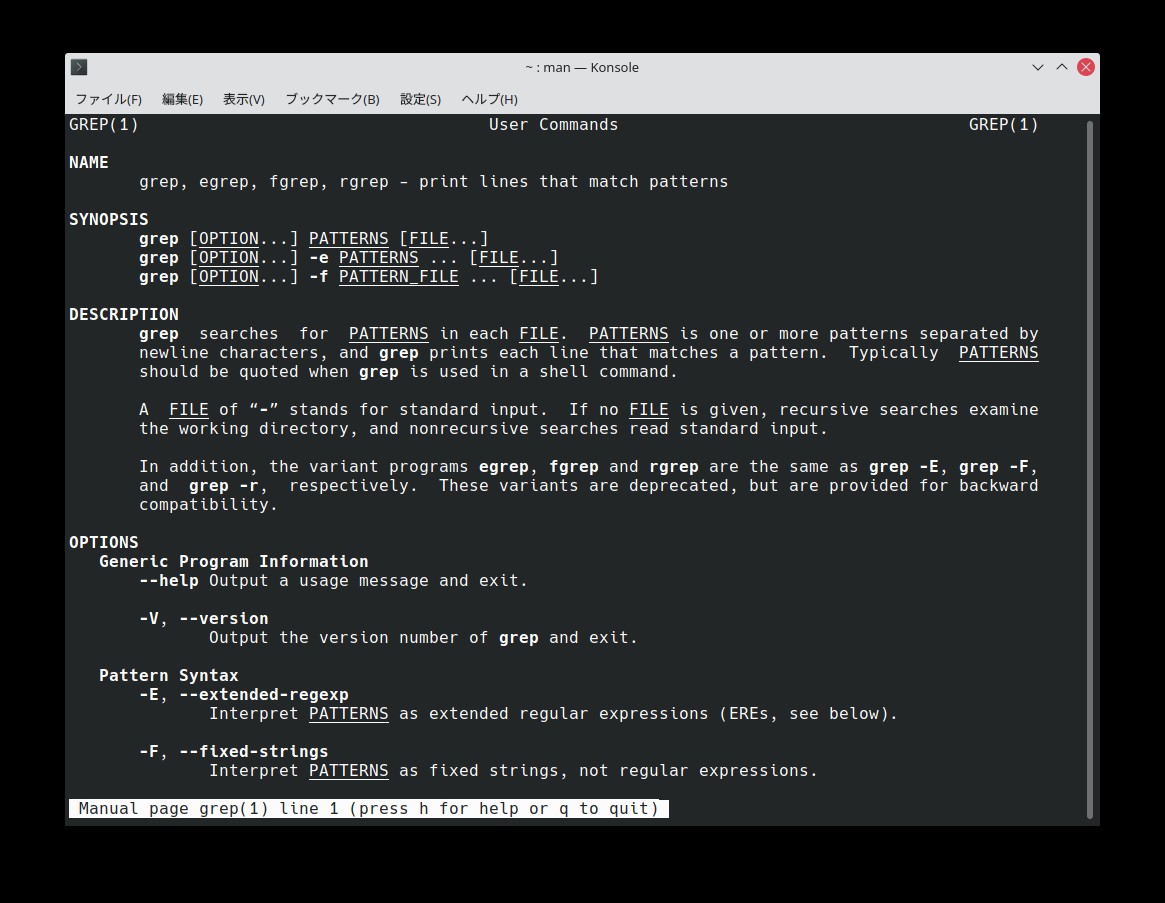
正規表現を利用したgrep
grepでよく聞かれる用語に、「正規表現」がある。Linux Essentialsのドキュメントの説明では、
「ファイル内のテキストのパターンを記述するために使用される」
とある。
しかし、どうも説明が難解なので、あれこれググってみると、どうやら「find」における「あいまい検索」のようなもののようだ。
例として、Linuxなら必ずホームディレクトリの隠しファイルとして存在する「.bashrc」内を検索してみよう。「.bashrc」は、主にBash(Linuxにおけるシェルプログラム)の各設定ファイルだ。
ホームディレクトリにあるファイルなので、パスは記載せずファイル名だけを検索文字の後に入力する。
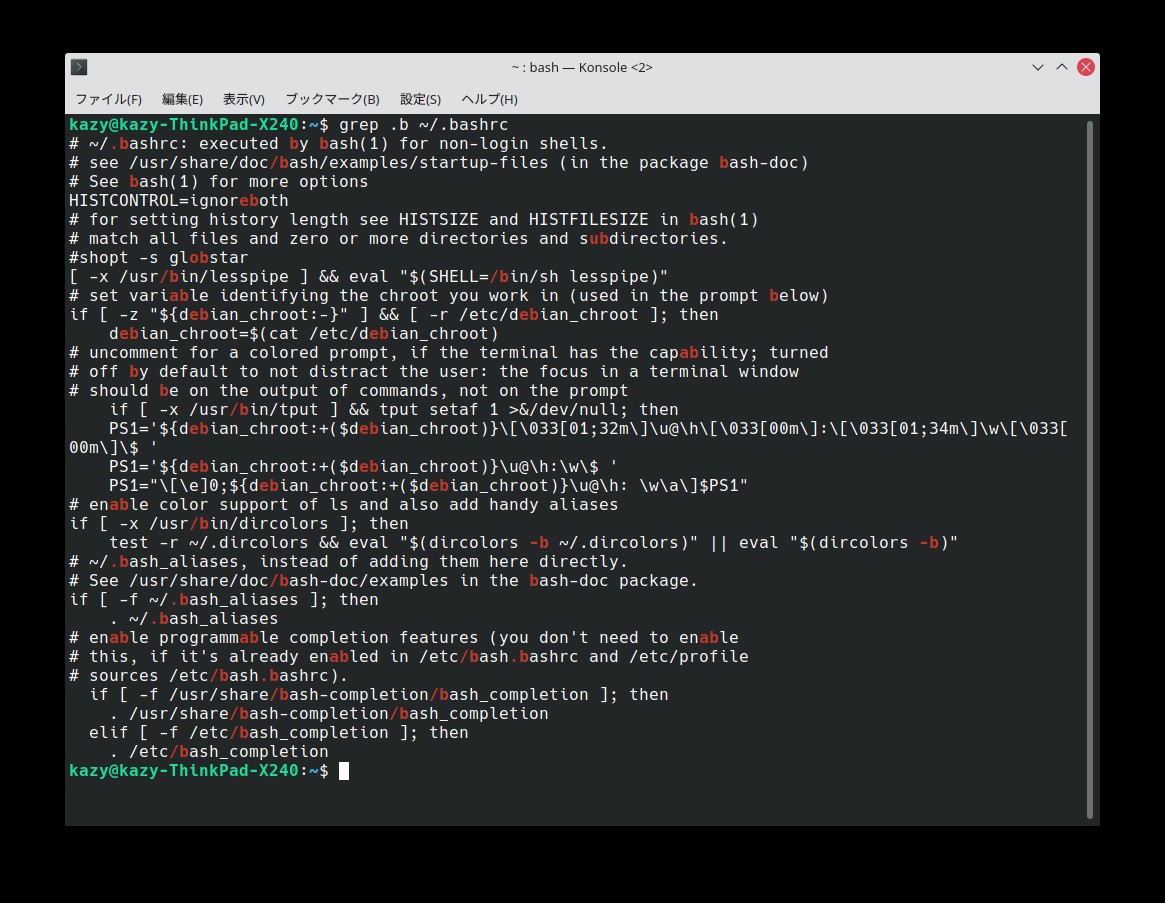
一文字検索
このファイルの中から、「bash」の「b」一文字だけで検索する場合、検索文字の前に「.(ピリオド)」をつけて検索する。
$ grep .b .bashrcこの検索結果は以下の通り。行の先頭でも末尾でも、とにかく「b」が含まれる文字列を全て抽出して表示する。
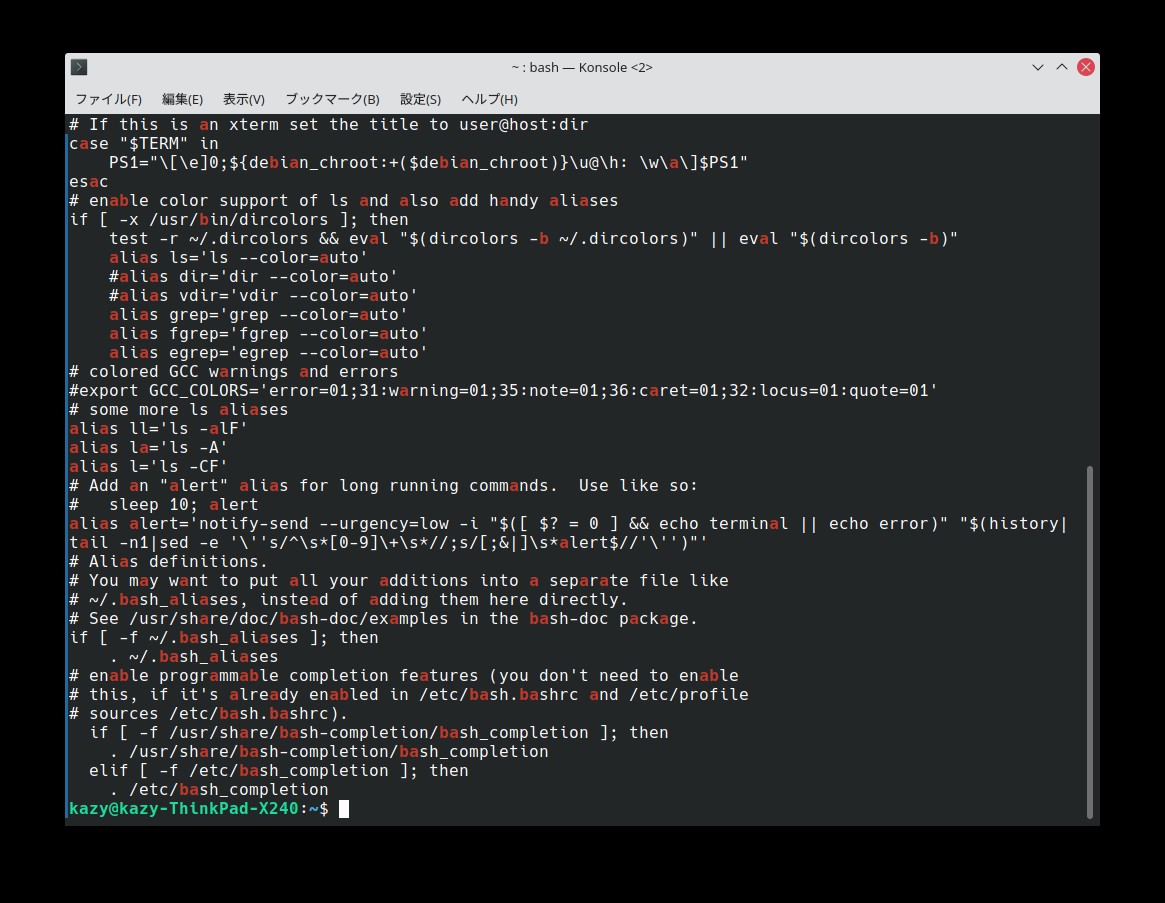
複数文字検索
次に、「ba」二文字以上の複数文字を含む文字列を検索する場合は、[ ]で括って検索する。
$ grep [ba] .bashrcこの検索結果は以下の通り。一文字検索と同様に、並び順はどうあれ、この二文字が含まれる文字列を抽出して表示する。
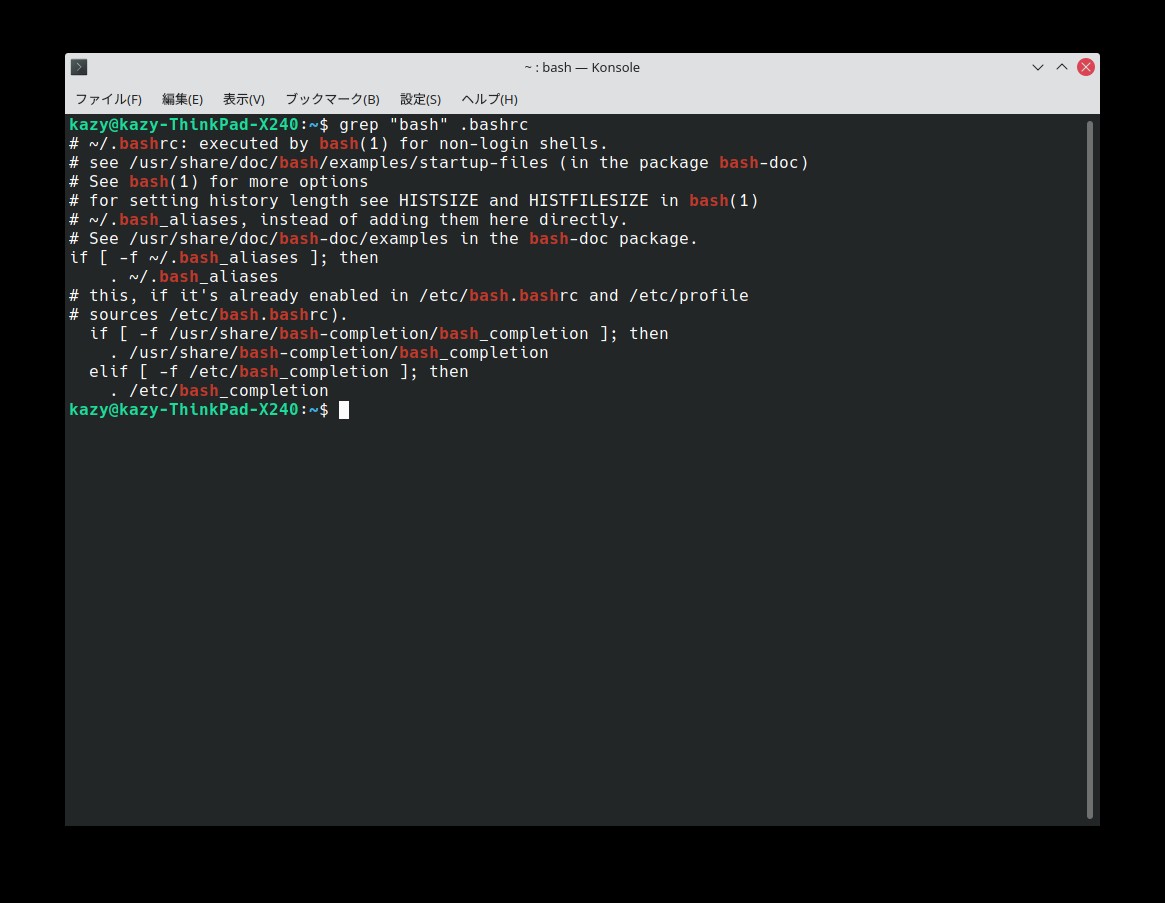
特定の文字列検索
次は、ズバリ「bash」という文字列(単語)を検索する場合。「” “(ダブルクォーテーション)」で括って検索する。
$ grep "bash" .bashrcこの検索結果は以下の通り。
先頭または末尾の特定文字検索
行の先頭または末尾の特定文字を検索する場合。「” “(ダブルクォーテーション)」で括ったのち、
- 行の先頭の場合は、文字の前に「^」をつけて
- 行の末尾の場合は、文字の後ろに「$」をつけて
検索する。例えば、先頭に「#(シャープ:コメントアウトする行につける)」がついている行や、末尾に「;」がついている行を検索するには、
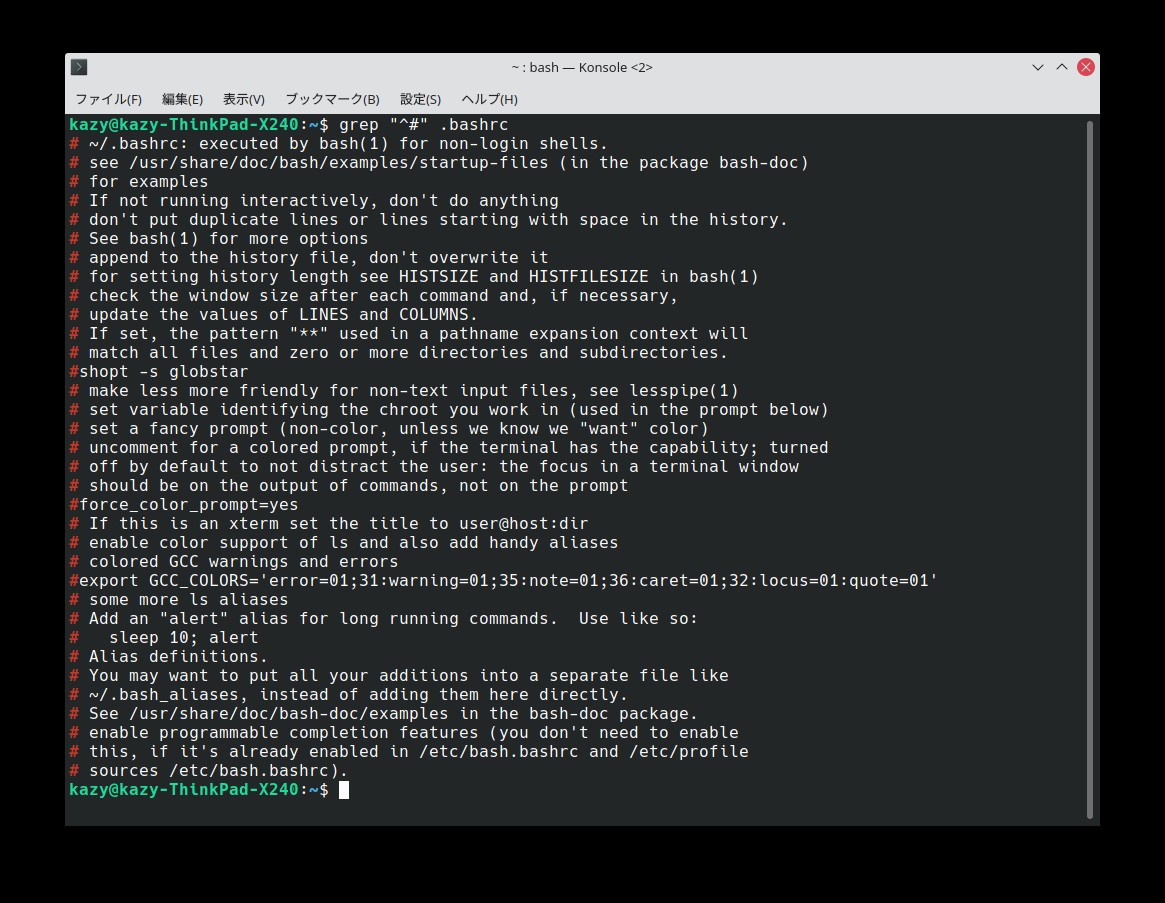
$ grep "^#" .bashrc
$ grep ";$" .bashrcと入力する。
この検索結果(行の先頭検索のみ)は以下の通り。
まとめ
ファイル検索が「find」で、ファイル内の文字列検索が「grep」だという区別はついた。さらに、grepにはいろいろなオプションで、より素早く検索できるということも理解できた。
文字列というよりは、その文字列が含まれる行を検索するのがgrepのようなので、「-v」(一致しない行を表示)や、行の先頭文字を指定する「^」オプションは、確かに便利かもしれない。
【ざっくりLinux!のおすすめ本】

コメント